






par Stéphane Lambert
![]() l est maintenant
temps de regarder comment fonctionne le moteur de la base de donnée
et d'optimiser les requêtes SQL. En effet, il est possible de gagner
considérablement en ressources machines rien que sur une
optimisation du code SQL. Là encore, il n'est pas question de magie,
mais de bien comprendre comment cela fonctionne, et d'utiliser à
propos les outils choisis, en l'occurrence les bases de donnée, qui
sont très coà»teuses en ressources systèmes. Bien sur, elles nous
rendent de fiers services mais leur utilisation abusive (ou
maladroite) peut provoquer de forts ralentissements, voir même
crasher le serveur. Il faut donc être très précautionneux de ce que
l'on va demander à l'outil. Comme d'habitude, il faut définir une
architecture en adéquation avec ses besoins, et l'utiliser le plus à
propos possible.
l est maintenant
temps de regarder comment fonctionne le moteur de la base de donnée
et d'optimiser les requêtes SQL. En effet, il est possible de gagner
considérablement en ressources machines rien que sur une
optimisation du code SQL. Là encore, il n'est pas question de magie,
mais de bien comprendre comment cela fonctionne, et d'utiliser à
propos les outils choisis, en l'occurrence les bases de donnée, qui
sont très coà»teuses en ressources systèmes. Bien sur, elles nous
rendent de fiers services mais leur utilisation abusive (ou
maladroite) peut provoquer de forts ralentissements, voir même
crasher le serveur. Il faut donc être très précautionneux de ce que
l'on va demander à l'outil. Comme d'habitude, il faut définir une
architecture en adéquation avec ses besoins, et l'utiliser le plus à
propos possible.
ECONOMISER LA MACHINE, C'EST EN FAIT POUVOIR LUI EN
DEMANDER PLUS
Un hébergeur Français bon marché, très
populaire chez les informaticiens et proche d'un fournisseur d'accès
gratuit à Internet, nous l'a cruellement rappelé à la fin de l'année
dernière. Fournissant des hébergements mutualisés (plusieurs sites
par machines), il s'est retrouvé avec certains sites reposant
intégralement sur des requêtes SQL lourdes voir inutiles, fausses,
et surtout lancées à tors et à travers. Certains de ces sites sont
devenus un peu connus, ont commencé à faire de l'audience, et ont
finalement faillis faire chavirer l'ensemble de la plate-forme
d'hébergement. Les bases de données, surchargées, refusaient souvent
de se lancer et de répondre aux requêtes, et renvoyaient
régulièrement des messages d'erreurs à tous les utilisateurs. Aux
heures de pointes, les sites n'étaient parfois même plus
consultables. Inutile de dire que la crédibilité d'un site internet
affichant des erreurs d'accès à la base SQL est sérieusement
entamée, et que de nombreuses personnes ont du reprendre leur
développement. Pour que le site Internet tienne la charge quand il
commence à être fréquenté, il vaut mieux qu'il repose sur des
fondations solides tant matérielles que logicielles. Quant à cet
hébergeur, il a du refondre son architecture matérielle, mais a
aussi perdu une grande part de sa crédibilité et de sa clientèle...
MODELISONS UN CATALOGUE : REVISIONS DE LA
TECHNIQUE...
Système d'Information (SI) :
Arborescence en Arbre...
Un garagiste expose sur le Web ses
modèles, afin de présenter ses nouveautées et surtout son stock en
temps réel (disponibilité de ses modèles). Il utilise ce que l'on
appèle un catalogue, sans caddy ni paiement en ligne (ce sont des
voitures...), mais avec navigation par catégorie/sous-catégorie,
affichage de la fiche-produit de la voiture, et possibilité de
recherche par marque de véhicule. Il limite sa fiche produit au nom,
au prix, et à la disponibilité de la voiture (on simplifie...). Ce
qui donne :
Un Produit possède 1 ou plusieurs
Créateurs (marques, fabricants). Un Créateur fabrique
0 ou plusieurs Produits. Ces Produits appartiennent
chacun à une et une seule Catégorie. Chaque Catégorie
contient 0 ou plusieurs Produits. Enfin, une Catégorie
peut avoir 0 ou plusieurs sous-Catégories, chaque
Catégorie ayant 0 ou une Catégorie parente.
D'où le MCD : 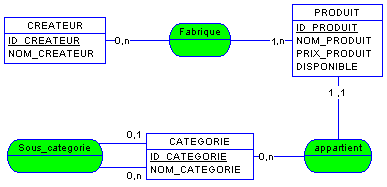
Qui entraîne le MLDR :
CREATEUR
(ID_CREATEUR, NOM_CREATEUR)
FABRIQUE (ID_CREATEUR,
ID_PRODUIT)
PRODUIT (ID_PRODUIT, #ID_CATEGORIE,
NOM_PRODUIT, PRIX_PRODUIT, DISPONIBLE)
CATEGORIE
(ID_CATEGORIE, #ID_PAR_CATEGORIE, NOM_CATEGORIE)
Qui génère le MPD : 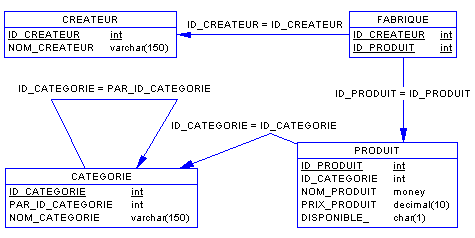
POUR SE PROTEGER, IL FAUT BIEN COLMATER LES JOINTURES
!!!
Prenons une requête d'extraction toute simple, et
regardons ce qu'il se passe : On recherche les modèles disponibles
de Véhicules de marques "Peugeot" de type "Décapotable", et leur
prix. L'identifiant ID_CREATEUR de "Peugeot" est ici "4", et
l'identifiant ID_CATEGORIE de "Décapotable" est "10".
SELECT *
FROM PRODUIT, FABRIQUE
WHERE PRODUIT.ID_CATEGORIE='10'
AND
FABRIQUE.ID_CREATEUR='4'
AND
PRODUIT.ID_PRODUIT=FABRIQUE.ID_PRODUIT
Regardons
maintenant ce que fait le moteur de la base :
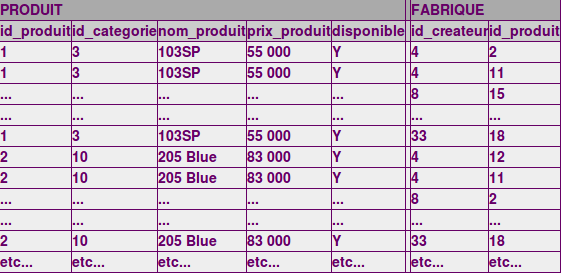
1°) Celui
interprète la requête ligne par ligne. Pour commencer, il met dans
un tableaux tous les éléments de PRODUIT et de
FABRIQUE, en faisant ce que l'on appelle un produit
cartésien : c'est à dire que pour chaque enregistrement de la
première table rencontrée, ici PRODUIT, il mettra en face
tous les enregistrements de la seconde table rencontrés un par un,
et ce pour chaque ligne. Si PRODUIT contient 250
enregistrements, et FABRIQUE 110, cette table temporaire et
intermédiaire comprendra 250*110=27500 lignes.
2°) Puis, il
supprime de cette même table temporaire les valeurs de id_catégories
différentes de '10'.
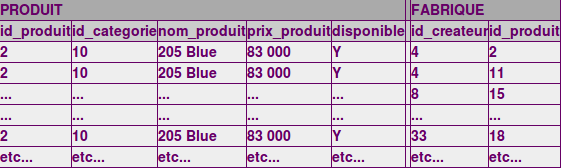
3°) Ensuite, il
supprime de cette même table temporaire les valeurs de id_createur
différentes de '4'.
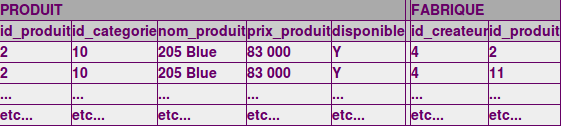
4°) Enfin, il
effectue la jointure demandée, et ne garde que les lignes dont
PRODUIT.ID_PRODUIT=FABRIQUE.ID_PRODUIT .

5°)
Eventuellement, si il le lui avait été demandé, c'est à ce stade
qu'il aurait interprété les commandes des instructions GROUP
BY, puis HAVING et enfin ORDER BY. Toutefois, il
est intéressant de constater que toutes les colonnes sont présentes
dans le tableaux, et que l'on a passé en mémoire à peu près 100 fois
l'intégralité de la quantité de données contenues dans ces seules
tables.
Imaginez un peu si le garagiste avait eu 100 000
Voitures réparties dans 250 Catégories, avec à peu près 970 marques
différentes ?
"Fà PAS GACHER", COMME DIRAIT L'AUTRE...
Reprenons la même requête, mais formulée un poil
différemment :
SELECT PRODUIT.NOM_PRODUIT,
PRODUIT.PRIX_PRODUIT
FROM PRODUIT, FABRIQUE
WHERE PRODUIT.ID_PRODUIT=FABRIQUE.ID_PRODUIT
AND PRODUIT.ID_CATEGORIE='10'
AND
FABRIQUE.ID_CREATEUR='4'
Regardons ce que
fais le moteur de la base :
1°) Tout d'abord, il récupère
dans un tableaux les éléments de PRODUIT demandés et ceux
nécessaires pour la requête, fais pareil pour FABRIQUE, et la
jointure étant spécifiée en premier, il ne prend que les lignes dont
PRODUIT.ID_PRODUIT=FABRIQUE.ID_PRODUIT .
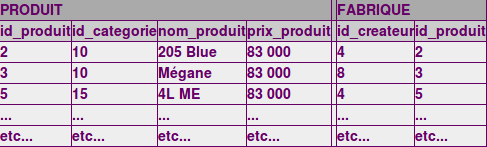
2°) Il enlève
les lignes dont id_categorie n'est pas égal à '10'
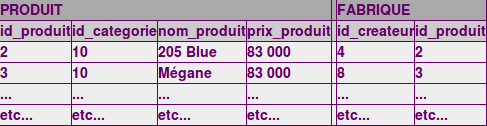
3°) Puis celles
où id_createur n'est pas égal à '4'

4°) Enfin, il ne
garde que les colonnes demandées dans la requête, c'est à dire le
nom, et le prix.

Si j'avais su,
par expérience ou connaissance du contexte, que la clause
FABRIQUE.ID_CREATEUR='4' était plus réductrice en
terme d'éléments que la clause PRODUIT.ID_CATEGORIE='10' , je
l'aurais alors mise avant celle ci, afin de réduire le plus possible
le nombre d'éléments stockés en mémoire, et donc les opérations
nécessaires pour les tris et traitements ultérieurs.
Il est
intéressant de remarquer que pour un obtenir un résultat similaire,
on a beaucoup moins tiré sur la machine, qui pourra donc accomplir
cette requête un plus grand nombre de fois simultanément, et donc
accueillir un plus grand nombre de visiteur sans souffrir...
QUI VEUT ALLER LOIN, MENAGE SA MONTURE
Sans
tomber non plus dans l'intégrisme inutile du coupeur de cheveux en
4, il est tout de même très clair que la simple formulation de la
requête SQL est lourde de conséquence sur les ressources et le temps
machine nécessaire pour sa simple exécution. On peut ainsi citer
quelques précautions simples qui allègeront simplement la charge
reposant sur le serveur :
- Mettre les jointures en premier :
Si n tables, alors (n-1) jointures.
- Placer les comparaisons les plus restrictives le plus
tôt possible :
cela fera toujours autant de lignes qui ne seront plus en mémoire, et que l'ordinateur n'aura plus à traiter dans le reste de sa requête.
- EVITER ABSOLUMENT "SELECT * FROM ..." :
Ne demandez que les colonnes nécessaires, c'est toujours ça de moins à garder en tableaux après la requête, et donc cela économise la mémoire. De plus, si un jour vous déplacez votre code, et que deux colonnes se trouvent inversées dans la nouvelle base, cela n'aura aucune conséquence pour votre développement.
- Comparer des colonnes de même type :
Un CHAR(150) est considéré du même type qu'un VARCHAR(150), mais différent d'un CHAR(152) ou d'un VARCHAR(148). Cela oblige le moteur de base de donnée à effectuer des conversions internes.
- Formuler les clauses de comparaison le plus précisement
possible :
En particulier, éviter de mettre des % partout dans les clauses LIKE, c'est très lourd à traiter...
- Mettre les identifiants en INT, et en AUTOINCREMENT
:
L'avantage principal de l'autoincrement est que pour chaque création d'enregistrement ne comprenant pas d'office son identifiant, le moteur se charge lui-même de lui en attribuer un [du type max(id)+1], ce qui évite des manipulations supplémentaires.
- Utilisez des INDEX :
Mais l'explication, là , ce sera pour la prochaine fois....
A bientôt...
Stéphane Lambert
http://www.vediovis.fr/
Spécialisé dans le
développement Web, Stéphane LAMBERT
a fondé VEDIOVIS PRODUCTIONS
en Mai 2000.
Son expérience couvre essentiellement les sites à
fortes audiences,
institutionnels ou audiovisuels.
Tous droits réservés - Reproduction même partielle interdite sans autorisation préalable

 vediovis.fr
vediovis.fr