






par Stéphane Lambert
![]() 'actualité nous le
prouve une fois encore : ce n'est pas parce que quelque chose est
nouveau que les principes fondamentaux ne sont plus valables. De
même qu'une entreprise est tributaire de son chiffre d'affaire et de
sa rentabilité, un développement informatique se juge selon un
minimum de règles élémentaires. On pourrait déjà citer : analyse,
cohérence de conception, modularité, lisibilité, et utilisation
censée des ressources matérielles et logicielles. Dans cette
optique, construire une belle base de donnée bien pensée, cohérente,
fonctionnelle, est déjà un premier pas. L'étape suivante est de
savoir comment la remplir, et surtout comment lire les données
qu'elle contient. Car les requêtes SQL pour interroger la base
peuvent être très gourmandes en ressources systèmes et temps
machine. Alors autant les formuler correctement afin de ne pas
surcharger le serveur et donc d'afficher les pages rapidement. Vous
pensez connaître la fonction "SELECT", la plus simple et la plus
utilisé ? Bien, alors vérifions cela...
'actualité nous le
prouve une fois encore : ce n'est pas parce que quelque chose est
nouveau que les principes fondamentaux ne sont plus valables. De
même qu'une entreprise est tributaire de son chiffre d'affaire et de
sa rentabilité, un développement informatique se juge selon un
minimum de règles élémentaires. On pourrait déjà citer : analyse,
cohérence de conception, modularité, lisibilité, et utilisation
censée des ressources matérielles et logicielles. Dans cette
optique, construire une belle base de donnée bien pensée, cohérente,
fonctionnelle, est déjà un premier pas. L'étape suivante est de
savoir comment la remplir, et surtout comment lire les données
qu'elle contient. Car les requêtes SQL pour interroger la base
peuvent être très gourmandes en ressources systèmes et temps
machine. Alors autant les formuler correctement afin de ne pas
surcharger le serveur et donc d'afficher les pages rapidement. Vous
pensez connaître la fonction "SELECT", la plus simple et la plus
utilisé ? Bien, alors vérifions cela...
SECTEURS NOUVEAUX ? FIASCOS IDIOTS...
Après
avoir vécu plusieurs années euphoriques, certaines Start Up Internet
sont actuellement à la peine. Car même si le marché des nouvelles
technologies est fabuleux, les perspectives de croissances
phénoménales, les investisseurs ont perdu de vue la notions la plus
fondamentale de l'économie : une entreprise doit être rentable. Et
bizarrement, ce point était absent de très nombreux Business Plan,
Businness Plan ayant permis à ne nombreuses sociétés de lever des
sommes astronomiques. Certaines d'entre elles n'existaient et ne
communiquaient que pour plaire à leurs investisseurs, et n'avaient
même aucune activité commerciale.
La réaction des financiers
est impitoyable : la majorité des investisseurs stoppent maintenant
leurs investissements, et demandent à leurs entreprises d'être
immédiatement rentables. Tout de suite. Et, comme nous sommes de bon
montons de Panurges, les valeurs boursières baissent, des projets
très prometteurs ne trouvent plus preneurs, et les décideurs
affichent une frilosité exagérée. On oublie que de nombreuses
entreprises font déjà d'énormes bénéfices, que le commerce
électronique affiche de très bons chiffres pour l'an 2000, et que
ceux ci vont tripler dans les deux ans. Que nous sommes en train de
transposer tout notre modèle économique, notre façon de travailler,
et d'organiser différemment notre société. Et surtout que c'est un
sacré chantier qui va générer une immense activité...
METIERS NOUVEAUX ?
SOYONS PROS !!!
L'analogie avec le développement est
évidente : Internet a permis à tout un chacun d'ouvrir un espace
chez un hébergeur, et à l'aide de livres devenus très accessibles et
facilement disponibles de commencer ses propres réalisations.
Intellectuellement, culturellement, ce fut une nouveauté fabuleuse.
Dans le même temps, les informaticiens traditionnels n'ont pas
toujours pris au sérieux ces nouvelles techniques "avec des images
qui bougent", et que "tout le monde touche". C'est pour cela que
nous trouvons beaucoup d'autodidactes dans les équipes techniques
Web. Même si les informaticiens issus de formations classiques sont
maintenant de plus en plus présent au sein des équipes de
développements Internet, il est important de professionnaliser les
méthodes de travail. De cesser l'amateurisme, de réapprendre
l'analyse et le génie logiciel. En bref, de devenir hyper
professionnel afin de ne pas faire l'erreur de se décrédibiliser
quand viendra pour nous aussi l'heure du bilan technique du travail
réalisé ces dernières années. Car nous aussi, nous serons jugés, en
quelque sorte, quand nos développements seront repris pour être
adaptés aux nouveaux besoins de l'entreprise, ou convertis aux
technologies futures :
Ce n'est pas parce qu'un domaine est
nouveau, que les principes fondamentaux ne sont plus valables.
LANGAGE SQL : SYNTAXE
D'EXTRACTION DES DONNEES
Le langage SQL (Structured
Query Langage, ou Langage d'Interrogation Structuré) date de la fin
des annés 70. (voir article Un peu d'histoire des SGBD sur le web et ailleurs
du 13 Novembre 2000). Nous allons déjà commencer par voir comment
lire les données, et ce que cela signifie réellement.
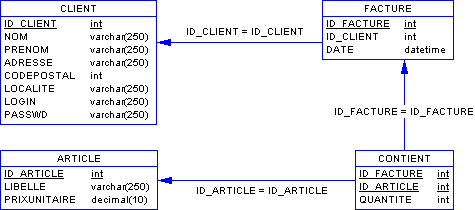
Appuyons-nous sur ce schéma de base :
Syntaxe de la commande SELECT :
SELECT [ALL | DISTINCT ] liste de colonnes
FROM Table_1,
table_2, ... , Table_n
WHERE ......
GROUP BY ......
HAVING ........
ORDER BY .......
COMPUTE .......
Exemples simples :
SELECT NOM, PRENOM
FROM CLIENT
renvoie le contenu
des colonnes NOM et PRENOM de la table CLIENT.
SELECT NOM as lastname,
PRENOM as firstname FROM CLIENT
renverra le même contenu, mais en renommant le nom des
colonnes de sorties.
SELECT LIBELLE,
PRIXUNITAIRE * 0.85 as prixpromo FROM ARTICLE
affichera le nom des articles et le prix diminué de 15%.
Il est donc possible d'effectuer des calculs directement au niveau
de la base de donnée, ce qui évitera de faire appel à une partie de
script spécialement développée pour l'occasion.
Détail des
clauses optionnelles :
La clause WHERE exprime les
conditions de recherches.
La clause GROUP BY groupe les
résultats par critères.
La clause HAVING permet de
restreindre les résultats en imposant une propriété.
La clause
ORDER BY trie les résultats suivant un critère de
qualification.
La clause COMPUTE génère des statistiques.
LANGAGE SQL : LA
CLAUSE WHERE
Les conditions de recherches peuvent faire
référence à des colonnes qui ne sont pas incluse dans la liste de
sélection. Elle est très utilisée pour définir ce que l'on appèle
des jointures :
SELECT CLIENT.NOM, CLIENT.PRENOM, FACTURE.DATE
FROM CLIENT, FACTURE
WHERE
CLIENT.ID_CLIENT=FACTURE.ID_CLIENT
renverra le nom et
le prénom des clients ayant des factures, ainsi que la/les date des
factures correspondantes. Il est important de faire une jointure sur
ID_CLIENT dans la clause Where, pour indiquer au moteur SQL que la
liaison entre les deux tables s'effectue sur cette colonne
'commune'. (Nous reviendrons dans un prochain article sur le
fonctionnement d'un moteur SQL).
Nous avons plusieurs outils
pour les types de condition :
Opérateur de
comparaison : = , > , < , >= , <=, <>
SELECT
LIBELLE, PRIXUNITAIRE
FROM ARTICLE
WHERE
PRIXUNITAIRE <>'100'
renverra les
articles dont le prix est différent de 100. Il est important de
mettre les côtes ' ' dans la clause Where, car sinon le moteur SQL
interprétera 100 comme étant une colonne.
Intervalles
: BETWEEN , NOT BETWEEN
SELECT LIBELLE,
PRIXUNITAIRE
FROM ARTICLE
WHERE PRIXUNITAIRE
BETWEEN '100' AND '200'
renverra les
articles dont le prix est compris entre 100 et 200.
Listes : IN , NOT IN
SELECT LIBELLE,
PRIXUNITAIRE
FROM ARTICLE
WHERE PRIXUNITAIRE
IN ('100','200','300)
renverra les
articles dont le prix est soit de 100, soit de 200, soit de 300.
Correspondances de chaînes : LIKE , NOT LIKE
Quelques jokers :
- % joker : toute chaîne de caractère
- - joker simple: un caractère, n'importe lequel
- [ ] un caractère de l'intervalle ou de l'ensemble spécifié
- [^ ] un caractère en dehors de l'intervalle ou de l'ensemble spécifié
SELECT LIBELLE, PRIXUNITAIRE
FROM ARTICLE
WHERE LIBELLE LIKE '%teu%'
renverra les articles dont le nom contient 'teu' (pelleteuse, par exemple....)
Valeurs inconnues : IS NULL, IS NOT NULL
SELECT LIBELLE, PRIXUNITAIRE
FROM ARTICLE
WHERE PRIXUNITAIRE IS NOT NULL
renverra les articles dont le prix existera, c'est à dire aura une valeur correspondante dans la table.
ATTENTION !!! En sql, NULL ne signifie pas 0 ,il représente une valeur indéterminée, il signifie 'rien', comme l'ensemble vide en Mathématique.
Combinaisons : AND , OR
SELECT LIBELLE, QUANTITE, DATE
FROM ARTICLE , CONTIENT, FACTURE
WHERE ARTICLE.ID_ARTICLE=CONTIENT.ID_ARTICLE
AND CONTIENT.ID_FACTURE=FACTURE.ID_FACTURE
AND PRIXUNITAIRE NOT BETWEEN '100' AND '200'
OR PRIXUNITAIRE='150'
renverra les articles, leur quantité par facture, et la date, et ceci pour les articles dont le prix n'est pas compris entre '100' et '200' ou est égal à '150'.
LANGAGE SQL : LES AGREGATS
Les fonctions
d'agrégats calculent des valeurs à partir des données d'une colonne
particulière. Les opérateurs d'agrégat sont : sum (somme), avg
(moyenne), max (le plus grand), min (le plus petit), et count (le
nombre d'enregistrements retournés).
SELECT
sum(PRIXUNITAIRE)
FROM ARTICLE, CONTIENT
WHERE
ARTICLE.ID_ARTICLE=CONTIENT.ID_ARTICLE
AND
CONTIENT.ID_FACTURE='123456'
renverra le montant
total de la facture '123456'
SELECT
avg(PRIXUNITAIRE)
FROM ARTICLE, CONTIENT
WHERE
ARTICLE.ID_ARTICLE=CONTIENT.ID_ARTICLE
AND
CONTIENT.ID_FACTURE='123456'
renverra le prix
moyens par article de la facture '123456'
SELECT
max(PRIXUNITAIRE)
FROM ARTICLE, CONTIENT
WHERE
ARTICLE.ID_ARTICLE=CONTIENT.ID_ARTICLE
AND
CONTIENT.ID_FACTURE='123456'
renverra le plus
grand prix de la facture '123456'
SELECT
min(PRIXUNITAIRE)
FROM ARTICLE, CONTIENT
WHERE
ARTICLE.ID_ARTICLE=CONTIENT.ID_ARTICLE
AND
CONTIENT.ID_FACTURE='123456'
renverra le plus
petit prix de la facture '123456'
SELECT
count(PRIXUNITAIRE)
FROM ARTICLE, CONTIENT
WHERE ARTICLE.ID_ARTICLE=CONTIENT.ID_ARTICLE
AND
CONTIENT.ID_FACTURE='123456'
renverra le nombres
d'articles figurants sur la facture '123456'
LANGAGE SQL : LA CLAUSE GROUP BY
La clause
GROUP BY, utilisée dans une instruction SELECT, divise
le résultat d'une table en groupe. Il y a actuellement 16 niveaux de
sous-groupes possibles.
La clause GROUP BY est présente dans les
requêtes qui comportent également des fonctions d'agrégats, ces
dernières produisant alors une valeur pour chaque groupe, également
appelé agrégat vectoriel.
SELECT NOM,
avg(PRIXUNITAIRE), sum(PRIXUNITAIRE), ID_FACTURE
FROM
ARTICLE , CONTIENT, FACTURE, CLIENT
WHERE
ARTICLE.ID_ARTICLE=CONTIENT.ID_ARTICLE
AND
CONTIENT.ID_FACTURE=FACTURE.ID_FACTURE
AND
FACTURE.ID_CLIENT=CLIENT.ID_CLIENT
GROUP BY
ID_FACTURE
renverra pour chaque
facture, par nom de client, le prix moyens ainsi que la quantité des
produits présents sur chaque facture.
LE LANGAGE SQL EST TRES SOUS-ESTIME. ET POURTANT...
Il n'est pas possible de tout voir en un seul article. La
prochaine fois, je détaillerais les clauses HAVING, ORDER BY, et
COMPUTE. Ensuite, je vous montrerais comment fonctionne un moteur de
base de donnée, afin de bien comprendre de quoi il s'agit, et de
montrer comment optimiser ses requêtes SQL. Ensuite, nous nous
amuseront un peu avec quelques requêtes un peu complexes, mais qui
permettront surtout d'avoir l'information en un seul accès à la base
de donnée, et de retoucher ensuite cette information le moins
possible dans le script lui-même. Autant limiter les accès à la
base, et récupérer le maximum d'information en une seule requête.
Car une fois que les requêtes principalement utilisées ont été
identifiées, il y a des méthodes très simples pour accélérer les
temps de réponse de la base sur ces requêtes. Et surtout, cela
évitera de retraiter les données dans de longues et lourdes routine
de programmation, souvent illisibles, incompréhensibles, et très
très coà»teuses en temps machine : il n'y a rien de pire qu'un trie
de données effectuée sous forme de pile (tableaux passés en
mémoires), alors autant éviter les lourdeurs inutiles.
Après,
tout est question de choix technologique et logicielle : un
programme ou un site reposant sur une base complexe devra peut être
utiliser un moteur SQL conséquent et plus professionel...
| << Lire la 5ème partie |
Stéphane Lambert
http://www.vediovis.fr/
Spécialisé dans le
développement Web, Stéphane LAMBERT
a fondé VEDIOVIS PRODUCTIONS
en Mai 2000.
Son expérience couvre essentiellement les sites à
fortes audiences,
institutionnels ou audiovisuels.
Tous droits réservés - Reproduction même partielle interdite sans autorisation préalable

 vediovis.fr
vediovis.fr